JC: pose estimation tools #1
11 Oct 2020 | by bartulem
Schweihoff et al. bioRxiv (2019) presented DeepLabStream (DLS), a deep-learning grounded, markerless, closed-loop and real-time pose estimation tool. The framework can run experiments autonomously, as it consists of a set of user-specified modules, like timers and stimulations, but also posture-based triggers that initialize a pre-defined cascade once a certain type of pose is detected in an experiment. To test DLS, the authors trained mice on a fully automated classical second-order conditioning task. The animals were taught, in a series of conditioning stages, to associate two unknown odors (rose, vanillin) with two visual stimuli (a high contrast black and white image), which had either positive or negative valence (because they were associated either with a reward or a loud tone). The process was fully automated, e.g. the animals were presented with the initial visual stimulus only once they were heading towards the screen. As a result, mice showed a clear preference for the positive conditioned odor. The second test involved optogenetically stimulating mice injected with the indicator Cal-Light whenever their head was directed a certain way in the environment. Irrespective of the spatial location in the environment, mice were reliably stimulated when their head was at a specific angle from a reference point.
Generally, the quality of closed-loop systems is defined by (1) the magnitude of the temporal delays between behavior detection and the resulting output and (2) the rate by which data could be obtained. To estimate the spatiotemporal resolution of postures that can be detected by the network, they compared the displacement of individual body parts between frames. The variability in the tracking output is due to both estimation errors and inhomogeneous movement of the animal during experiments. The average Euclidean distance between successive frames in this set of experiments was smaller for the neck (2±3 mm) and tail root (2±4 mm) points, and larger for the nose (4±9 mm) point, while the head direction varied 11.8±47.5° between consecutive frames. For a camera sampling at 30 fps, the hardware that achieved the best performance in real-time tracking with 30±7 ms (and 32.75±0.36ms for optogenetics) required 64 GB DDR4 RAM and 12 GB NVidia GeForce RTX 2080. Finally, the authors note certain drawbacks, or spaces for further improvement of this method: (1) it’s a solution for short to mid-length experiments (<day) as it lacks the capability to automatically process the large amounts of raw video data, (2) if global behavior is tracked at 30 fps, detailed movements that happen on short timescales (like whisker and pupil movements) are currently off limits.
Zimmermann et al. bioRxiv (2020) created FreiPose, a versatile learning-based framework that directly captures 3D motion of tracked points with high precision. Marker-based approaches restrict tracking to specific sites (usually ones the animal can tolerate) and can even obstruct natural movement, while marker-free methods yield 3D reconstructions based on post-hoc 2D output triangulations (which assumes resolving ambiguities in each view separately). The purpose of FreiPose is to circumvent these travails by reconstructing detailed poses and single body part movements directly in 3D. This is done on synchronized multi-view videos and calculations of sparse reconstructions of on-body keypoints, processing each frame independently. Processed data are also assigned reconstruction confidence, allowing potentially erroneous frames to be identified quickly. FreiPose compares favorably to DeepLabCut (DLC) in terms of accuracy (median 3D error of 4.54 vs. 7.81 mm for DLC) and reliability (percentage of samples below a maximum 7.5 mm error bound of 82.8% vs. 48.1% for DLC), but also the number of cameras required to reach a given accuracy and data efficiency (lower median error with the same number of labeled samples).
Combining FreiPose with neural recordings in the motor cortex of freely moving rats showed that roughly half of the recorded neurons were tuned to postural features (satisfyingly replicating our results). In addition, they modified the Berman approach to perform low-dimensional behavioral embedding. All poses were transformed into a body-centric reference frame, distances between keypoints to each other and to the floor were pushed through PCA (20 PCs explained 95% of the variance) to allow for a Morlet-wavelet transform of the components at 0.5-15 Hz frequencies. The combined temporal and spatial features were embedded into 2 dimensions via t-SNE, and the areas around peak densities were separated with the watershed algorithm. This approach yielded 4 clearly distinguishable behavioral clusters: locomotion, grooming, rearing and inspection of nearby environments, similar to other studies which focused on freely-moving rodents. The authors also looked at whether there was any indication of neuronal representation of spontaneous movements, concentrating on paw trajectories. As expected, an ensemble of recorded neurons in motor cortex was modulated by contralateral paw movements, and a more detailed analysis showed that this tuning is seemingly independent of the underlying behavioral context (i.e. neurons respond in the same way to paw trajectories, regardless of whether they occur during locomotion or inspection), a finding that should resonate more within the community. Finally, they optogenetically stimulated freely moving rats, retrained FreiPose and trained a support vector machine to classify timepoints into “stimulated” or “not stimulated”, a procedure which had an average accuracy between 59 and 73%.
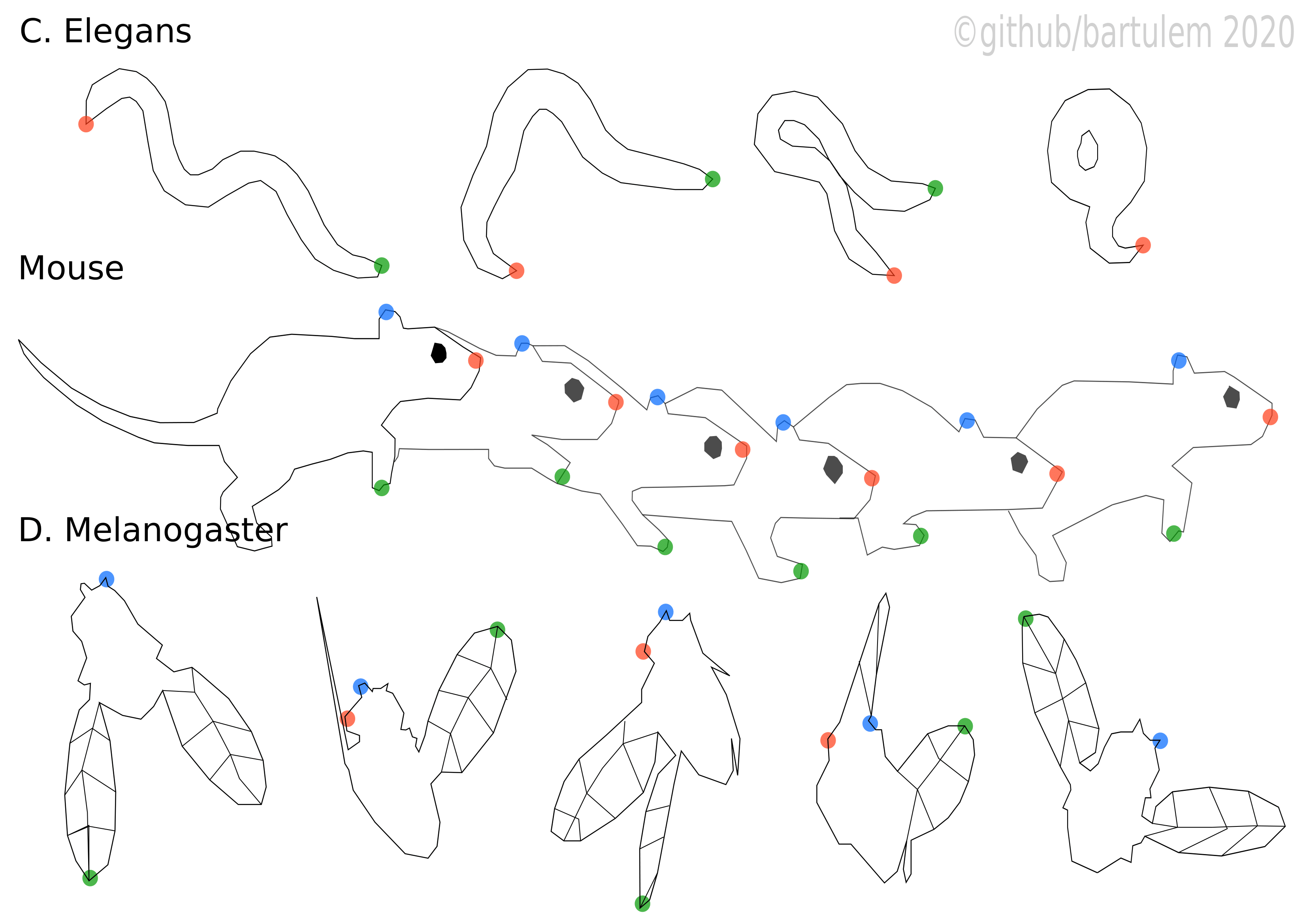
Wu et al. bioRxiv (2020) developed Deep Graph Pose (DGP) for animal pose estimation, a probabilistic graphical model built on top of deep neural networks. It was inspired by human pose estimation algorithms which used graphical models to prevent overfitting. This is useful because animal tracking is often contaminated by frames where labels are briefly lost, despite the large effort that goes into labeling. Essentially, DGP models the targets as continuous random variables (as opposed to discrete), leveraging observed and hidden information to infer the locations of unobserved targets via graph semi-supervised inference. Specifically, since targets are unobserved in most frames, several constraints are imposed: (1) the temporal smoothness constraints between successive frames (which work well in practice as small constant values), (2) the spatial potentials, which impose distance constraints on specific marker dyads (they can be set to c/dij where dij is the average distance between markers i and j and c is a small, positive scalar value, a strategy that leads to robust results), and (3) the potential parameterized by a neural network. The goal of the method is to estimate the posterior probability over locations of unlabeled targets with structured variational inference (Gaussian graphical model), as the highly non-linear neural network potentials prevent exact calculations.
The performance of DGP was compared to that of DLC in a mouse paw-tracking dataset. DGP not only outperformed DeepLabCut (DLC) by reducing the number of “glitch” frames (where target tracking is lost), but also had more unimodal “confidence maps” (i.e. more localized “belief” of the network where the targets were) and considerably lower test errors when evaluated across multiple random subsets of the training set. The authors further show that such tracking output can lead to better behavioral segmentation (e.g. when separating still vs. moving paw frames). Finally, they combined object tracking with convolutional autoencoders (CAE), as interpreting latent features after unsupervised dimensionality reduction of behavioral videos has proved to be difficult. The idea is that the tracked targets encode information about the location of designated body parts, while the CAE latent vectors encode the remaining variance in the frames. This structure allows researchers to “disentangle” the variability into more interpretable subspaces. After fitting CAEs that consider marker output by DLC or DGP as conditional inputs to both encoding and decoding networks of the CAE, the mean square error of reconstructed frames was decreased for both methods, but networks trained with DGP exhibited better performance. To test the extent of disentanglement between CAE latents and the output markers, they checked how changing either individual marker positions or latent values affects the accuracy of reconstructions for DLC and DGP. In either case, the decoding worked better for DGP, demonstrating that the CAE-DGP network learns how to disentangle the markers and the latents better.
The pose estimation field hasn’t been resting idly since the advent of DLC, as different paths are being taken to improve reconstruction error rates (in 2D and 3D), and the speed of reconstruction (preferably functioning in real time, such that one could perform closed-loop experiments), which should also lead to more robust subsequent behavioral segmentation. The three approaches outlined here resonate with these needs and offer solutions that compare favorably to DLC on a set of various measures. I am particularly excited by the prospect of optimizing pose estimation to offer high fidelity real-time tracking (DeepLabStream), as it would refine enticing possibilities of combining the study of naturalistic behaviors with closed-loop experimentation. Secondly, approaches that target reconstruction refinement in 3D (e.g. FreiPose) are specially important to those of us interested in 3D features of behavior, and findings like the paw movement tuning not being embedded in a specific behavioral context should be explored more in the future. Finally, the idea of integrating target tracking with convolutional autoencoders (Deep Graph Pose) to account for residual variance in behavioral videos bodes well with further lowering reconstruction error rates, as does the usage of graphical models with aiding behavioral segmentation.